
Elevation
기초통계학 (3) - 표본과 표본분포(Z분포, 카이제곱분포, t분포, F분포) 본문
저번 편에서 categorical data의 개수를 통계량으로 하여 얻을 수 있는 분포인 초기하분포와 이항분포에 대해 구체적으로 다루었다. 이번에는 연속형 모집단에서 추출한 표본의 통계량을 바탕으로 한 표본분포들에 대해 정리해 보자.
표본평균의 분포 (feat. 정규분포)
먼저 표본평균이라는 통계량의 성질에 대해, 다음처럼 유도할 수 있다.

표준오차(standard error)는 통계량의 변동성으로 통계량 자체의 정확성과 관련있다. 일반적으로 각 표본에서의 변동성을 표준편차(standard deviation)으로 부르므로 서로 다른 개념이다.
그렇다면 표본평균은 어떤 분포를 따를까? 모집단이 만약 정규분포 $N(\mu, \sigma^2)$을 따른다면, 서로 독립인 정규분포는 선형결합이 가능하기에 표본평균 $\overline{X}$는 당연히 정규분포 $N(\mu, \frac{\sigma^2}{n})$을 따르게 된다. 놀라운 사실은 모집단이 정규분포를 따르지 않는 경우에도, 표본 크기 $n$이 충분히 크면 $\overline{X}$는 정규분포를 근사적으로 따른다는 것이다. 이를 중심극한정리(CLT)라 한다.
$$\frac{\overline{X}-\mu}{\sigma/\sqrt{n}}\;\dot{\sim}\;N(0, 1)$$
일반적으로 CLT는 n이 30 이상인 경우 적용 가능하나, 이것이 확실한 guideline이라기보다는 모집단의 형태를 먼저 살펴보고 결정하는 것이 좋다고 한다.
이항분포의 정규근사
CLT에 의하면, $n$이 충분히 크다면 이항분포 역시 비정규분포($Ber.$)의 합이기에 $N$으로 근사 가능하다. 이항분포 $B(n, p)$를 따르는 확률변수 $X$는 $n$이 충분히 클 때($np\geq5, n(1-p)\geq5$) 근사적으로 정규분포를 따른다.
$$\frac{X-np}{\sqrt{np(1-p)}}\;\dot{\sim}\;N(0, 1)$$
다만, 이산형 분포(이항분포)를 연속형 분포(정규분포)로 근사할 때, 계급의 수가 많지 않은 경우 오차가 생길 수 있다. 히스토그램과 정규분포곡선을 함께 그려보면, 가령 $P(7<X<10)$을 구하는 경우에 실제로 해당하는 계급은 8, 9밖에 없으나 정규분포곡선에서는 7 초과 10 미만의 범위에서 넓이를 계산하므로 과대 근사하게 된다. 따라서 히스토그램 최소 단위의 절반만큼 조정하여 $P(7.5<X_N<9.5)$을 이용하는 것이 타당하다. 이를 연속성 수정(continuity correciton)이라 한다.
표본분산의 분포 (feat. 카이제곱분포)
먼저 카이제곱분포의 정의부터 소개한다. 확률변수 $Z_1, Z_2, \cdots, Z_k$가 $N(0,1)$의 랜덤표본일 때, 다음과 같이 정의되는 통계량의 분포를 자유도 k인 카이제곱분포라 한다.
$$Z_1^2 + \cdots + Z_k^2 \; \sim \; \chi^2(k)$$
서로 독립인 두 카이제곱분포를 합한 것은 두 분포의 자유도를 더한 값을 자유도로 하는 카이제곱분포가 된다. 이를 카이제곱분포의 가법성이라 한다($V_1\sim\chi^2(k_1), V_2\sim\chi^2(k_2)\Rightarrow V_1 + V_2 \sim \chi^2(k_1 + k_2)$). 표준정규분포에서 추출한 표본의 제곱의 합이므로 0부터 무한대까지 뻗어나가며 오른쪽 긴 꼬리의 비대칭 분포를 보인다.
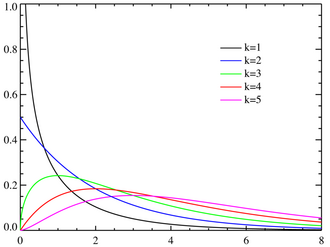
그럼 왜 저런 통계량을 만들어서 쓰는가? 제곱의 합이라는 점에서 짐작했겠지만, 표본분산의 분포가 카이제곱분포와 관련있다. 정규분포 $N(\mu, \sigma^2)$에서의 랜덤표본의 표본분산 $S^2$에 대해 다음이 성립한다.
$$\frac{(n-1)S^2}{\sigma^2}\;\sim\;\chi^2(n-1)$$
카이제곱분포에서 상수들을 곱해주는 것으로 표본분산의 분포를 얻을 수 있음을 확인할 수 있다. 증명은 다음과 같다.
$$\textrm{i})\;\sum{(\frac{X_i-\mu}{\sigma})^2}\sim\chi^2(n),\;\;\textrm{ii})\;(\frac{X_i-\mu}{\sigma})^2 \sim\chi^2(1)$$
$$\begin{align} \frac{\sum{(X_i-\mu)^2}}{\sigma^2}&=\frac{\sum{(X_i-\overline{X}+\overline{X}-\mu)^2}}{\sigma^2}\\ &=\frac{\sum{(X_i-\overline{X})^2}}{\sigma^2}+\frac{n\sum{(\overline{X}-\mu)^2}}{\sigma^2}\\ \therefore \chi^2(n)&=\frac{(n-1)S^2}{\sigma^2}+\chi^2(1)\\ \chi^2(n-1)&=\frac{(n-1)S^2}{\sigma^2}\end{align}$$
스튜던트화된 표본평균의 분포 (feat. t-분포)
비슷한 흐름으로 t분포의 정의에 대해 먼저 알아보자. t분포는 정규분포와 카이제곱분포의 결합으로 볼 수 있다. 확률변수 $Z$가 표준정규분포를 따르고 $V$가 자유도 k인 카이제곱분포를 따르며 두 분포가 서로 독립일 때, 다음과 같이 t분포를 정의한다.
$$T=\frac{Z}{\sqrt{V/k}} \;\sim t(k)$$
t분포는 표준정규분포처럼 0을 중심으로 좌우 대칭이나 꼬리가 좀 더 두껍다. 자유도가 커질수록 표준정규분포와 유사해지며, 자유도가 30 이상이면 표준정규분포로 대체 가능하다.
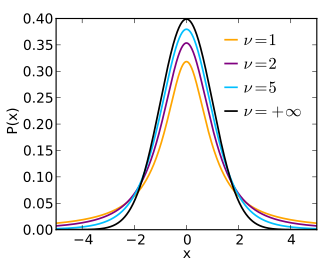
정규분포에서 추출한 랜덤표본 $X_i$에 대해 다음이 성립한다. t분포의 정의로부터 쉽게 유도할 수 있다.
$$\frac{\overline{X}-\mu}{S/\sqrt{n}}\sim t(n-1)$$
표본평균을 모수 $\mu$와 $\sigma$를 이용해 표준화한 분포가 표준정규분포를 따르는 것과 달리, $\sigma$를 표본표준편차 $S$로 대체한 것은 t분포를 따른다는 것을 알 수 있다. 이는 모집단에 대한 정확한 정보 대신에 표본의 통계량을 사용하였기에 그만큼 (특히 자유도가 낮을수록) 변동성이 커져 정규분포에 비해 꼬리가 두꺼워진다고 해석할 수 있겠다.
그렇다면 왜 굳이 $\sigma$를 $S$로 대체하는가? 이는 주어진 표본만을 가지고 모집단을 맞추는 표본평균의 예측 과정에서 모수를 알 수 없다는 현실적인 이유 때문이다. 우리의 관심사는 $\mu$인데 $\mu$를 맞추기 위해 $\sigma$가 필요하다는 것은 비현실적이므로, $\sigma$를 잘 따라가는 $S$로 대체하여 쓰는 것이다.
두 정규모집단에서의 표본분산 비의 분포 (feat. F-분포)
F분포는 두 카이제곱분포로부터 정의된다. 자유도 $k_1$, $k_2$인 카이제곱분포를 따르는 확률변수 $V_1$, $V_2$가 서로 독립일 때, F분포를 다음과 같이 정의한다.
$$ F=\frac{V_1/k_1}{V_2/k_2}\;\sim F(k_1, k_2)$$

F분포의 정의로부터 다음의 두 성질을 유도해낼 수 있다. 특히 t분포와 F분포의 관계는 주목해 볼 만한데, $Z^2\sim \chi^2(1)$인 것처럼 t분포의 제곱은 F분포를 따라간다. 확률밀도함수의 모양도 그렇고 두 쌍을 나란히 기억해 두면 쉽게 떠올릴 수 있다.
$$\frac{1}{F(k_1,k_2)}\sim F(k_1,k_2)$$
$$\left\{ t(k) \right\}^2 \sim F(1,k)$$
F분포는 추후 두 모집단에서 각각 표본을 뽑아 비교하는 경우에 사용된다. 두 정규분포 $N(\mu_1, \sigma^2_1)$, $N(\mu_2, \sigma^2_2)$에서 뽑은 랜덤표본 $X_i$, $Y_i$가 서로 독립이면 다음이 성립한다.
$$\frac{S^2_1/\sigma^2_1}{S^2_2/\sigma^2_2}\sim F(n_1-1, n_2-1)$$
결국 각 분포들은 추정 및 검정 과정에서 자연스럽게 등장하기 때문에, 처음에는 정의를 그냥 받아들이고 익숙해질 수 있도록 하는 것이 중요하다.
정규분포 분위수 대조도 (Q-Q plot)
지금까지 각 표본분포들의 정의를 살펴보면, 카이제곱분포, t분포, F분포 모두 모집단의 분포가 정규분포임을 전제하고 있는 정규분포의 파생분포이다. 따라서 통계적 추론 과정에서 정규모집단 가정은 매우 중요하므로, 뽑은 표본에 대해 Q-Q plot을 그려 정규모집단 가정을 검토할 수 있다.
만약 Q-Q plot을 그려 보았을 때 모집단이 정규분포가 아닐 가능성이 크다면, non-parametric test 등 다른 방법을 고려하여야 한다.
'정리 > 통계학' 카테고리의 다른 글
| 기초통계학 (6) - 이표본 가설 검정 (0) | 2025.09.09 |
|---|---|
| 기초통계학 (5) - 가설 검정(Z-test, t-test) (0) | 2025.05.10 |
| 기초통계학 (4) - 추정 (0) | 2025.05.10 |
| 기초통계학 (2) - 표본분포 (0) | 2025.04.28 |
| 기초통계학 (1) - 측도, 표본, 확률과 확률분포 (0) | 2025.04.28 |


