
Elevation
기초통계학 (5) - 가설 검정(Z-test, t-test) 본문
통계적 추론의 또 다른 방법인 검정에 대해 알아볼 것이다. 추정이 사전 정보 없이 모수의 값을 직접 예측하는 것이라면, 검정은 모수에 대한 주장을 받아들일지의 여부를 표본을 통해 판단하는 간접적 추론으로 볼 수 있다. '기존 주장이 틀렸고 나의 주장이 맞다'는 것을 입증해야만 하는 과학의 세계에서, 검정은 그 도구로 유용하게 쓰인다.
가설 검정은 다음의 단계로 진행된다.
1. 가설 설정
2. 검정의 유의수준 $\alpha$ 설정
3. 표본을 바탕으로 검정통계량 계산
4. 검정통계량을 바탕으로 기각역이나 p-value를 구해 결론 도출
통계적 가설
귀무가설($H_0$): 알려진(현재 믿어지는) 가설. 모집단의 모수를 하나의 값 또는 구간으로 표시한다.
대립가설($H_1$): 연구자가 주장하고자 하는 가설. 귀무가설을 제외한 나머지 영역.
→ 연구자는 추출한 표본으로 귀무가설을 기각할 충분한 증거가 있음을 보이고, 따라서 대신 대립가설을 채택해야 한다고 주장하는 것이 기본적인 목표가 된다.
대립가설이 포함하는 범위에 따라 단측 가설과 양측 가설로 나뉜다.
검정 오류
1종 오류(type I error: $\alpha$): 실제로는 귀무가설이 맞으나, 잘못하여 대립가설을 채택할 확률
2종 오류(type II error: $\beta$): 실제로는 대립가설이 맞으나, 잘못하여 귀무가설을 채택할 확률
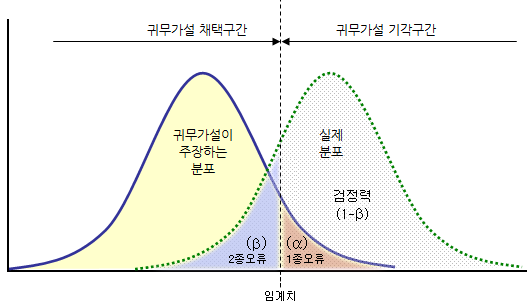
귀무가설과 대립가설의 정의를 생각해 보았을 때, 1종 오류가 더 심각하다고 여겨지므로 $\alpha$를 고정시켜 놓은 상태에서 $1-\beta$를 크게 하는 검정을 선호한다. 이때 $\alpha$가 낮을수록 통계적으로 유의한(귀무가설을 기각할 수 있는) 결과를 얻었다고 말할 수 있는 판정의 기준이 더 까다로워지므로, $\alpha$를 유의수준(significance level)이라 한다. $1-\beta$는 실제 대립가설이 참일 때 대립가설을 채택할 확률을 의미하므로, 이를 검정력이라 한다.
유의수준은 선행 연구를 참고하여 결정하는데, 일반적으로는 $\alpha=0.05$가 많이 쓰인다.
기각역과 p-value
기각역과 p-value는 검정의 결론을 도출하는 두 가지 방법이다.
먼저 기각역(rejection region)은 귀무가설을 기각하게 되는 영역을 정해, 계산된 검정통계량이 기각역에 속하면 귀무가설을 기각하는 방식이다. 따라서 귀무가설이 맞다는 전제 하에 검정통계량의 표본분포를 살펴보고, 표본분포 상에서 확률이 $\alpha$가 되는 지점을 경계로 기각역을 정한다. 기각역의 방향은 대립가설에 따라 단측검정(one tailed test), 양측검정(two tailed test)로 나뉜다.
$$P(H_0\;\textrm{reject}\;|\;H_0\,\textrm{true}) = \alpha$$
다만 기각역 방법은 유의수준이 달라지면 새로운 기각역을 반복해서 계산해 줘야 하고, 기각의 강도를 알 수 없다는 단점이 있다. 이를 해결할 수 있는 방법이 p-value인데, 특별히 새로운 방법은 아니고 현재 관측한 값 이상으로 대립가설을 입증하는 데이터가 관찰될 확률을 유의확률(p-value)이라 하여, p-value가 $\alpha$보다 작으면 귀무가설을 기각하는 방법이다. 즉 기각역이 미리 확률이 $\alpha$인 지점을 경계로 정해 놓는 느낌이라면, p-value는 실제 표본에 대해 확률을 계산해서 비교하는 방법이라고 보면 되겠다.
$$\textrm{Reject }H_0\textrm{ if p-value}<\alpha$$

p-value로 검정의 강도를 확인할 수 있으나, 표본 수 n이 너무 크면 검정통계량의 분산이 지나치게 작아져 조금의 차이로도 p-value가 매우 작아질 수 있다. 그래서 효과 크기(effect size)를 함께 체크할 필요가 있다.
모평균에 대한 가설검정: 모분산을 아는 경우 (Z-test)
이제 가설 검정을 해 볼 준비가 되었으니, 예제를 통해 검정 과정을 따라가 보자.
| 전자제품 제조사는 자사의 최신 가전제품이 평균 전력 소모가 기존의 평균 전력 소모량 50W 보다 감소하여 제품 효율이 증가했다고 주장하고 있다. 평균 전력 소모량은 표준편차 4.5W인 정규분포를 따른다고 가정하자. 랜덤하게 선택된 40개의 최신 가전제품을 사용하여 평균 전력 소모를 조사한 결과, 평균이 48W로 나타났다고 한다. 유의수준 5%에서 제조사의 주장이 통계적으로 유의미한지 검정하시오. |
1. $H_0: \mu=50$, $H_1: \mu<50$
2. $\alpha=0.05$
3. 검정통계량 $\overline{X}$는 정규분포를 따라가므로, 귀무가설이 맞다는 가정 하에 표준화하면
$\frac{\overline{X}-50}{4.5/\sqrt{40}}=-2.81 \sim Z$
4. (기각역) $-z_{0.05}=-1.645$이므로, 기각역은 $Z<-1.645$이다. → Reject $H_0$
(p-value) $P(Z<-2.81)=0.0224 < \alpha$ → Reject $H_0$
이렇게 간단하게 Z-test를 수행해 볼 수 있다.
모평균에 대한 가설검정: 모분산을 모르는 경우 (t-test)
모분산 $\sigma$에 대해 알려져 있지 않다면, 표본분산 $S$를 대신 사용하여 $\overline{X}$를 표준화한다. 이렇게 스튜던트화된 표본평균은 t-분포를 따르므로 t-test 검정을 수행한다.
이때 '정규분포와 달리, t-분포는 CLT를 적용받지 않으므로 정규모집단 가정이 필요하지 않을까?' 라는 의문이 들 수 있다. 그러나 표본의 크기가 충분히 크다면 정규모집단의 가정이 완화될 수 있다. 이를 t분포의 robustness라고 한다. 그러면서 동시에 표본의 크기가 충분히 크다면 t-분포 대신 표준정규분포를 사용할 수 있으므로, 표본의 크기가 크다면 사실상 모분산을 알지 못하더라도 Z-test를 수행하면 되는 셈이다.
아까와 비슷한 예제를 한 번 풀어보자.
| 전자제품 제조사는 자사의 최신 가전제품이 평균 전력 소모가 기존의 평균 전력 소모량 50W 보다 감소하여 제품 효율이 증가했다고 주장하고 있다. 랜덤하게 선택된 50개의 최신 가전제품을 사용하여 평균 전력 소모를 조사한 결과, 평균이 48W, 표준편차가 5W로 나타났다고 한다. 유의수준 5%에서 제조사의 주장이 통계적으로 유의미한지 검정하시오. |
1. $H_0: \mu=50$, $H_1: \mu<50$
2. $\alpha=0.05$
3. $\overline{X}$를 표준화하면, 귀무가설이 맞다는 가정 하에 검정통계량은
$\frac{\overline{X}-50}{5/\sqrt{50}}=-2.82 \sim t(49)$
4. $P(T<-2.82)=0.0035 < \alpha$ → Reject $H_0$
Bootstrapping
그러나 실제 상황에서는 표본 수를 충분히 얻기 어려운 경우가 많고, 모집단이 정규모집단임을 전제하기 어려운 경우도 많다. 이런 경우 non-parametric한 접근 방법을 쓰거나 bootstrapping을 통해 표본 수를 늘려야 한다.
Bootstrap sample은 원래의 표본에서 복원추출로 얻은 랜덤 표본이다. 즉 Bootstrapping은 표본을 모집단이라고 생각하고 다시 원하는 만큼 복원추출을 하여 원하는 수의 표본을 얻어내 표본 분포를 추정하는 방법이라고 볼 수 있다.
'정리 > 통계학' 카테고리의 다른 글
| 기초통계학 (7) - 모분산에 관한 추론 (0) | 2025.09.10 |
|---|---|
| 기초통계학 (6) - 이표본 가설 검정 (0) | 2025.09.09 |
| 기초통계학 (4) - 추정 (0) | 2025.05.10 |
| 기초통계학 (3) - 표본과 표본분포(Z분포, 카이제곱분포, t분포, F분포) (0) | 2025.05.05 |
| 기초통계학 (2) - 표본분포 (0) | 2025.04.28 |
