
Elevation
기초통계학 (10) - 상관분석과 단순회귀분석 본문
두 변수 간의 관계를 살펴보고 싶은 경우, 상관분석이나 회귀분석을 수행한다. 상관분석(correlation analysis)은 두 변수 사이에 관계가 있는지, 있다면 어느 정도 강도로 존재하는지를 모상관계수를 추론함으로써 확인한다. 회귀분석(regression analysis)은 두 변수 사이의 함수 관계를 확인하는 것으로, 회귀분석을 통해 한 변수의 값으로부터 다른 변수의 값을 예측할 수 있다. 검정에 비해 비교적 잘 알려진 통계적 분석 방법이니만큼 가볍게 정리하고 넘어간다.
상관분석
모상관계수 $\rho$는 공분산을 각 표준편차의 곱으로 나눈 값이다. 표본 크기가 $n$일 때 표본분산은 모분산의 $1/n$배, 표본표준편차는 모표준편차의 $1/\sqrt{n}$배임을 감안하면, 표본상관계수 $r$의 식은 분모, 분자에 곱해진 값들이 상쇄되어 모상관계수의 식과 동일해짐을 확인할 수 있다.
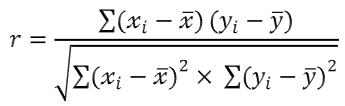
우리가 늘 해왔던 것처럼, 표본상관계수 $r$의 검정은 $r$을 적절히 변형한 검정통계량이 특정 분포를 따르도록 하여 가능해진다. 놀랍게도, 다음과 같은 검정통계량은 수학적으로 t-분포를 따름이 알려져 있다.
$$ T = \sqrt{n-2} \frac{r}{\sqrt{1-r^2}} \, \sim \, t(n-2)$$
단순회귀분석
회귀분석의 목적은 다른 변수에 영향을 주는 설명변수(독립변수) $X$를 알고 있을 때, 영향을 받는 변수인 관심변수(종속변수) $Y$의 값을 예측하는 것이다. 현실 세계에서 대부분의 경우, 알려진 설명변수만으로 $Y$가 고정되어 나오지 않으며 임의성(randomness)이 존재하여 같은 입력값으로도 다른 결과가 나올 수 있기 때문에 확률적 모형을 예측 모델로서 주로 사용한다.
이를 바탕으로 한 단순선형회귀분석의 기본적 모형은 다음과 같다.
$$ Y = \alpha + \beta x + e$$
랜덤오차 $e$의 존재로 개별값 $Y$에 대한 예측은 불가능하므로, 우리는 $Y$의 조건부 기댓값 $E(Y|X=x) = \hat{y}$를 찾는 것을 목표로 한다. 랜덤오차에 대한 적절한 수학적 가정을 하면, $\hat{y}$를 분석할 때 오차를 배제하는 것이 가능해진다(물론 해당 가정이 올바른지 사후 검증하는 과정을 필요로 한다). 단순선형회귀분석의 가정은 다음과 같다.
- 선형성: $E(e) = 0$
- 등분산성: $Var(e) = \sigma^2 > 0$
- 독립성: $e$는 서로 독립.
이러한 가정들이 어떠한 의미를 갖는지 잠시 생각해 보면, 이 가정을 통해 랜덤오차는 $e \sim (0, \sigma^2)$으로 일정한 평균과 표준편차로 표현되는 분포를 갖게 되며, $x$의 값에 관계없이 서로 독립적이다. $Y$의 식에서 $\alpha + \beta x$는 입력값에 따라 정해지는 상수이므로, $Y$ 역시 $e$의 분포에 의존한다. 따라서 $Y$ 역시 $x$의 값에 관계없이 $Y \sim (\alpha + \beta x , \sigma^2)$의 분포를 가진다고 볼 수 있는 것이다.
이어서, 모형을 완성하기 위해 회귀계수를 추정해 보자. 회귀계수의 추정은 잔차 $\hat{e_i} = y_i - \hat{y_i}$(잔차는 오차의 실관측값이다)로부터 이루어진다. 최소제곱법(method of least squares)은 잔차제곱의 합을 최소로 만드는 직선을 추정한다. $\hat{\alpha}, \hat{\beta}$ 각각에 대해 잔차 제곱의 합을 편미분하여, 그 값이 0이 되도록 하는 $\hat{\alpha}, \hat{\beta}$를 찾으면 된다. 결과는 아래와 같다.
$$ \hat{\alpha} = \overline{y} - \hat{\beta} \overline{x}$$
$$ \hat{\beta} = \frac{\sum{(x_i - \overline{x})(y_i - \overline{y})}}{\sum{(x_i - \overline{x})^2}} = \frac{S_{xy}}{S_{xx}}$$
표기의 편의를 위해, 각 변수에 대한 편차 곱의 합을 $S_{xy}, S_{xx}$와 같이 나타내었다. 기울기 $\hat{\beta}$ 의 의미는, $x$가 1단위 증가할 때 $ \triangle E(Y)$으로 해석할 수 있다.
단순회귀분석의 평가
만든 모형의 설명력을 측정해 보자. 자료의 편차 $y_i - \overline{y} = (\hat{y_i} - \overline{y}) + (y_i - \hat{y_i})$로 분해할 수 있는데, 앞 부분은 모형으로 구한 기댓값이 평균과 얼마나 떨어져 있는지를 나타내므로 모형이 설명하는 부분, 뒷 부분은 기댓값과 실관측값의 차이이므로 모형이 설명하지 못하는 부분이라고 볼 수 있다. 이를 총 편차의 제곱의 합으로 확장해 보면 아래 식과 같다.
$$ \sum{(y_i - \overline{y})^2} = \sum{(\hat{y_i} - \overline{y})^2} + \sum{(y_i - \hat{y_i})^2} $$
$$ SST = SSR + SSE $$
(좌변의 식에 대입해 계산해 보면, 두 항의 곱으로 표현되는 새 항이 나타나지만 $\sum(y_i - \overline{y})$로 묶을 수 있어 값이 0이 된다)
Y 자체의 특성이자, 전체 변동량인 SST(총제곱합)은 회귀식으로 설명 가능한 변동인 SSR(회귀제곱합)과 설명 불가능한 변동인 SSE(잔차제곱합)으로 나눌 수 있다는 것이 이 식의 의미이다.
따라서 SST 중 SSR의 비율은 회귀식의 설명력을 나타내기에 좋은 지표가 될 것이다. 이를 결정계수(coefficient of determination)이라 하고 $r^2$으로 표기한다. $r^2$로 표기하는 이유는, 결정계수를 상관계수 $r$의 제곱으로 얻을 수 있기 때문이다. SSR과 SST의 정의에서 도출이 가능하다. 직관적으로도, 상관계수의 절댓값이 클수록 해당 자료는 강한 선형성을 가지고, 따라서 해당 자료를 최적의 선형 모델로 추정했을 때 모델의 설명력이 높은 것은 타당하다고 볼 수 있다.
$$ r^2 = \frac{SSR}{SST} = ( \frac{S_{xy}}{\sqrt{S_{xx}}\sqrt{S_{yy}}} ) ^2 $$
일반적으로 결정계수가 0.6 이상이면 설명력이 좋은 것으로 여겨지나, 설명변수가 증가할수록 결정계수는 증가하는 경향이 있어 결정계수가 높은 모델이 무조건 좋은 모델이라고 할 수는 없다.
단순회귀분석에서의 추론
최소제곱법으로 회귀계수의 추정'값'을 찾는 데 성공했다면, 우리의 다음 관심 대상은 회귀계수의 신뢰 구간 추정 및 가설 검정 방법일 것이다. 이러한 추론을 위해서는 전술한 오차에 관한 3개의 가정 외에도 하나의 가정이 더 필요하다. 바로 정규성 가정으로, 오차가 (평균이 0이고 표준편차가 $\sigma$인) 정규분포를 따른다는 것이다. $e$와 $Y$가 정규성을 만족하면 추정과 검정을 위한 다양한 모수적 분석 방법을 사용할 수 있게 된다.
먼저 회귀분석의 유의성 검정부터 진행해 보자. $X$와 $Y$가 선형적 관계가 있음을 증명하는 것이므로 귀무가설은 $\beta = 0$가 된다. 총 $n$개의 $x_i, y_i$ 세트에서 $SSR$은 오직 $\hat{\beta}$에 의해서만 결정되므로 자유도가 1이고, $SSE$의 경우 각각의 오차가 독립적이면서 $\hat{\beta}, \hat{\alpha}$ 두 개의 외부 조건이 존재하므로 자유도는 n-2가 된다. 결과적으로 각각을 자유도로 나눠주어 구한 검정통계량이 F-분포를 따름이 알려져 있다.
$$ F = \frac{SSR / 1}{SSE / n-2} = \frac{MSR}{MSE} \, \sim \, F(1,n-2)$$
회귀식이 유의할수록, 분산 중 회귀식에 의한 변동량 SSR은 커지고 우연에 의한 변동량 SSE은 줄어들 것이므로, F 통계량의 값이 커져 결과적으로 유의확률이 작게 나올 것이다. $Y$ 전체의 분산을 잘 쪼개서 검정을 수행한다는 것이 꽤 인상적인데, 이와 관해서는 추후 분산분석 파트에서 자세히 알아볼 것이다.
잔차분석
오차의 관측값인 잔차를 분석해서 오차에 관한 기존 가정들이 타당함을 입증해야, 회귀분석의 추론들이 의미를 갖게 된다. 잔차분석은 잔차도(residual plot)를 이용해서 진행한다. 잔차도는 설명변수 $X$를 x축으로, 스튜던트화해 표준화한 잔차들을 y축으로 하여 그린 산점도이다. 잔차도를 보고 각각의 가정의 위배 여부를 대략적으로 파악한다.
- 선형성: 0에 관해 대략 대칭적으로 분포하는가?
- 등분산성: X값에 따라 잔차의 산포가 크게 다르지 않은가?
- 독립성: 점들이 특정한 패턴으로 나타나지는 않는가?
- 정규성: 95%의 점들이 (-2, 2) 사이에 존재하는가?
잔차도에도 패턴이 발견된 경우, 추가로 설명 가능한 정보가 버려졌다는 의미이다. 이 경우 비선형 모델을 사용하거나, 적절한 자료의 변형을 통해 모델의 적합도를 높여야 한다.
'정리 > 통계학' 카테고리의 다른 글
| 기초 통계학 (11) - 중회귀분석 (0) | 2026.02.10 |
|---|---|
| 기초통계학 (9) - 이산 자료에 관한 추론 2 (적합도/동질성/독립성 검정) (0) | 2025.10.05 |
| 기초통계학 (8) - 이산 자료에 관한 추론 1 (모비율) (0) | 2025.09.18 |
| 기초통계학 (7) - 모분산에 관한 추론 (0) | 2025.09.10 |
| 기초통계학 (6) - 이표본 가설 검정 (0) | 2025.09.09 |